To completely separate sites within the Wagtail admin, we need to make changes to page and collection permissions and do some patching of the user management, workflow, and history systems. My previous post covered the mechanics of how we introduce monkey patches into our project. In this post I am going to explain how we have customized Wagtail 5.1’s new PagePermissionPolicy to preserve our version of multitenancy.
SuperAdmins
It is impractical for us to add our developers to the actual Admin groups of the hundreds of sites
on the system, so we invented concept we call “superadmins”. Superadmins are users who the system
pretends are in the “Admin” group for whichever site they’re currently logged in to. In this way,
our system presents each site to a superadmin as if it’s the only site on the server and lets us
see exactly what an actual admin of the site sees. is_superadmin is a boolean field on our user
model:
class User(AbstractUser):
"""
Replaces the auth.User model with our customized version.
"""
is_superadmin = models.BooleanField(
default=False,
verbose_name='Super Admin',
help_text='Enable this flag to make this user a Super Admin, which causes the system to treat them like they '
'are an Admin on whatever site they are logged into.'
)
Page Permission Patches
Prior to Wagtail 5.1 we were patching wagtail.admin.auth.user_has_any_page_permission,
wagtail.admin.navigation.get_pages_with_direct_explore_permission, and
wagtail.core.models.UserPagePermissionsProxy.__init__.
In Wagtail 5.1, UserPagePermissionsProxy and get_pages_with_direct_explore_permission are
both deprecated and permission checking has been consolidated into a new PagePermissionPolicy
class. I was initially planning to try subclassing PagePermissionPolicy so I could explicitly
initialize it with the current site. Because PagePermissionPolicy is instantiated 27 places in 17
different files, switching out the policy class for a subclass is impractical. So I have gone back
to our monkey patching strategy.
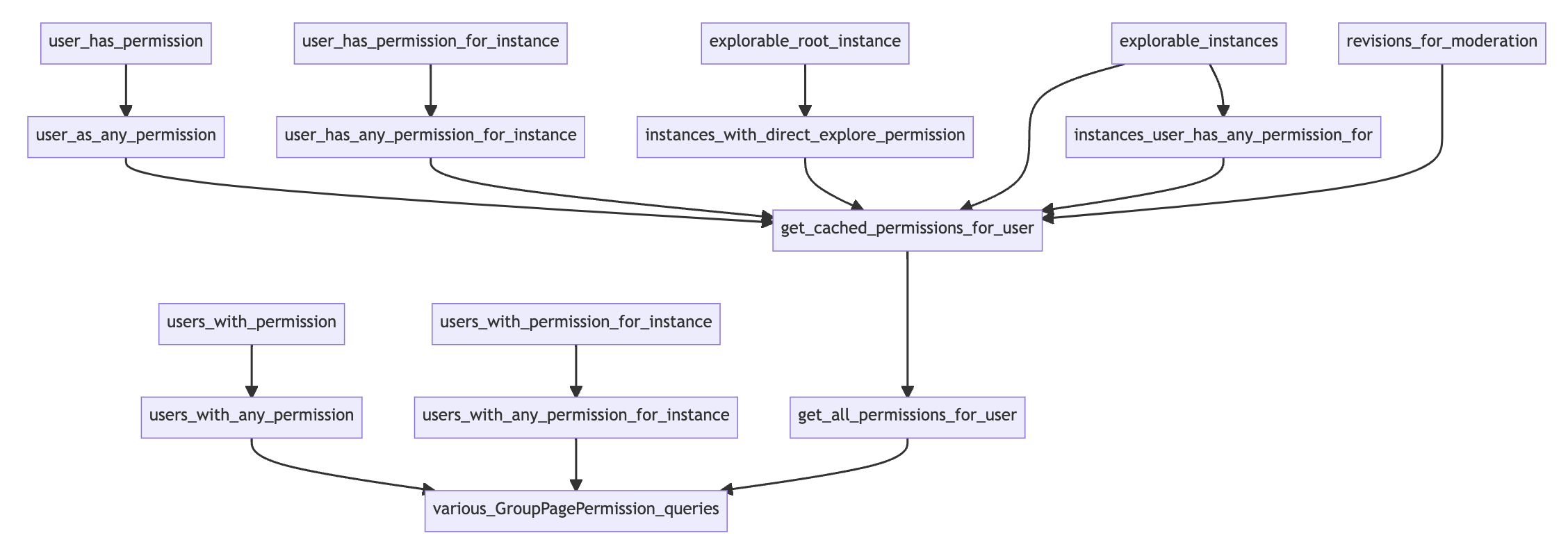
When I diagram the method calls within PagePermissionPolicy, I see that they nearly all go
through get_all_page_permissions_for_user - the main method used to query the
GroupPagePermissions table. The results of this query are cached and used by other parts of the
Wagtail admin interface as needed.
To enforce our site separation requirement, I added a filter for pages on the current site:
return GroupPagePermission.objects.filter(
group__user=user,
page__path__startswith=site.root_page.path
).select_related(
"page", "permission"
)
To allow superadmins to behave as site admins, I explicitly filtered for the site admin group:
# Give them the permissions of the site admin group
group = Group.objects.filter(name=f'{site.hostname} Admins').first()
return GroupPagePermission.objects.filter(group=group).select_related(
"page", "permission"
)
Combining those two, our full version of get_all_page_permissions_for_user is:
def mutitenant_get_all_page_permissions_for_user(self, user):
if not user.is_active or user.is_anonymous or user.is_superuser:
return GroupPagePermission.objects.none()
# BEGIN PATCH
request = get_current_request()
if not request:
logger.error(
'In PagePermissionPolicy.mutitenant_get_all_page_permissions_for_user but could not get the request.'
)
return GroupPagePermission.objects.none()
# So now restrict checks to permissions for the current site
site = Site.find_for_request(request)
if user.is_superadmin:
# Give them the permissions of the site admin group
group = Group.objects.filter(name=f'{site.hostname} Admins').first()
return GroupPagePermission.objects.filter(group=group).select_related(
"page", "permission"
)
else:
# filter for current user and for permissions relevant only to this site
return GroupPagePermission.objects.filter(
group__user=user,
page__path__startswith=site.root_page.path
).select_related(
"page", "permission"
)
# Getting this function used is covered below
The behavior changes are both relatively straightforward; the tricky bit is getting the site. In the
code above that is taken care of by
Site.find_for_request
plus our get_current_request method. This could be a problem if get_all_permissions_for_user were
called from code that does not have access to the request. Fortunately almost all the places that
instantiate PagePermissionPolicy are views or, if the instantiating code is not itself a view, the
methods that need the permission policy are only executed from a view. For example, the is_shown
method for MenuItem subclasses is only executed when a user is viewing the admin UI.
Looking at the diagram above, you can see in the next to bottom row, in addition to
get_all_permissions_for_user, there are two other methods that query GroupPagePermission.
Neither of them appear to be in use in the current Wagtail codebase. But for the sake of
completeness, I have monkey patched them too:
def mutitenant_users_with_any_permission(self, actions, include_superusers=True):
"""
2023-07-22 cnk: I patched this because it had a query in it but as of Wagtail 5.1.1 this
method is not in use, nor is users_with_permission which delegates to this method
"""
# User with only "add" permission can still edit their own pages
actions = set(actions)
if "change" in actions:
actions.add("add")
# BEGIN PATCH
request = get_current_request()
if not request:
logger.error('In PagePermissionPolicy.mutitenant_users_with_any_permission but could not get the request.')
return get_user_model.objects.none()
# So now restrict checks to permissions for the current site
site = Site.find_for_request(request)
groups = GroupPagePermission.objects.filter(
permission__codename__in=self._get_permission_codenames(actions),
group__name__startswith=site.hostname
).values_list("group", flat=True)
q = Q(groups__in=groups)
# Superadmins will have all page permissions because Admins do
q |= Q(is_superadmin=True)
# END PATCH
if include_superusers:
q |= Q(is_superuser=True)
return (
get_user_model()
._default_manager.filter(is_active=True)
.filter(q)
.distinct()
)
def multitenant_users_with_any_permission_for_instance(
self, actions, instance, include_superusers=True
):
"""
2023-07-22 cnk: I patched this because it had a query in it but as of Wagtail 5.1.1 the only
place this is used is send_moderation_notification. Since this is for an instance, it naturally
filters for just one site - but we need to add in superadmins.
"""
# Find permissions for all ancestors that match any of the actions
ancestors = instance.get_ancestors(inclusive=True)
groups = GroupPagePermission.objects.filter(
permission__codename__in=self._get_permission_codenames(actions),
page__in=ancestors,
).values_list("group", flat=True)
q = Q(groups__in=groups)
# BEGIN PATCH
# Superadmins will have all page permissions because Admins do
q |= Q(is_superadmin=True)
# END PATCH
if include_superusers:
q |= Q(is_superuser=True)
# If "change" is in actions but "add" is not, then we need to check for
# cases where the user has "add" permission on an ancestor, and is the
# owner of the instance
if "change" in actions and "add" not in actions:
add_groups = GroupPagePermission.objects.filter(
permission__codename=get_permission_codename("add", self.model._meta),
page__in=ancestors,
).values_list("group", flat=True)
q |= Q(groups__in=add_groups) & Q(pk=instance.owner_id)
return (
get_user_model()
._default_manager.filter(is_active=True)
.filter(q)
.distinct()
)
And finally, to get our versions of these files used, we import PagePermissionPolicy and replace the functions:
from wagtail.permission_policies.pages import PagePermissionPolicy
PagePermissionPolicy.get_all_permissions_for_user = mutitenant_get_all_page_permissions_for_user
PagePermissionPolicy.users_with_any_permission = mutitenant_users_with_any_permission
PagePermissionPolicy.users_with_any_permission_for_instance = multitenant_users_with_any_permission_for_instance
Collection Permission Patches
In addition to managing their own pages, site owners need to be able to manage their own images and
documents. Permissions for images and documents are controlled by permissions set on the collection
that contains them. When we create a new site, we create a collection for it and allow the site’s
Admin group the ability to create collections underneath that parent collection. Permissions for
managing the collections are managed by the CollectionManagementPermissionPolicy and permissions
that control access to images and documents are controlled by the
CollectionOwnershipPermissionPolicy. Both of those use the CollectionPermissionLookupMixin
to query GroupCollectionPermission. In the diagrams below, methods coming from
CollectionPermissionLookupMixin are denoted with a “*”. Prior to Wagtail 5.1 we were
patching CollectionPermissionLookupMixin.check_perm and
CollectionPermissionLookupMixin.collections_with_perm but as of Wagtail 5.1 most of the
collection permission logic goes through CollectionPermissionLookupMixin.get_all_permissions_for_user.
Document and Image Permissions
The more important set of permissions is in the CollectionOwnershipPermissionPolicy class. This
class decides what permissions a user has over the images and documents stored in the site’s
collections. As you can see in the diagram below, all of the policy’s queries flow through
get_all_permissions_for_user, so we can enforce our rules by patching that one method.
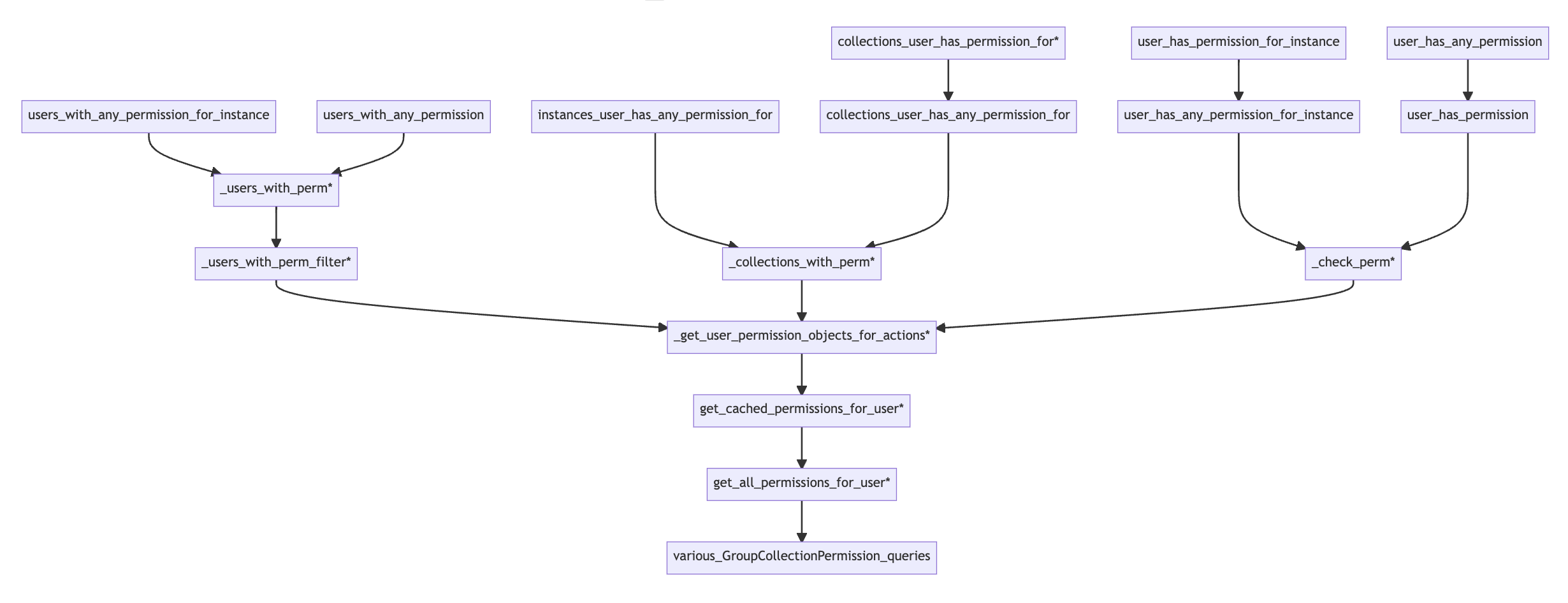
As with page permissions, the first time a Collection model is accessed triggers a query to the
GroupCollectionPermission model (via get_all_permissions_for_user) and caches the user’s
collection permissions on the user object. So we make similar patches to the ones we made above for
pages. We add one line to filter the collection tree to restrict it to permissions for this site and
a different change to assign superadmins to the site’s Admin group. Our naming contention ensures the
we can find that site’s base collection by knowing the site for this request.
def mutitenant_get_all_collection_permissions_for_user(self, user):
"""
This method does a lot of the filtering for collections the user has access to. If we can get a
request here, we can enforce a lot of our special cases right here.
1. Users should only see collections for the current site - even if they have permissions on
other sites. So we need to filter permissions for the site's root collection.
2. If the user is a superadmin, we need to fake assigning them to the site's Admin group.
"""
# For these users, we can determine the permissions without querying
# GroupCollectionPermission by checking it directly in _check_perm()
if not user.is_active or user.is_anonymous or user.is_superuser:
return GroupCollectionPermission.objects.none()
# BEGIN PATCH
request = get_current_request()
if not request:
logger.error('In CollectionPermissionLookupMixin.mutitenant_get_all_permissions_for_user but could not get the request.')
return GroupCollectionPermission.objects.none()
# So now restrict checks to the collections for the current site
site = Site.find_for_request(request)
collection = Collection.objects.filter(name=site.hostname).first()
if user.is_superadmin:
group = Group.objects.filter(name=f'{site.hostname} Admins').first()
return GroupCollectionPermission.objects.filter(
group=group,
collection=collection
).select_related("permission", "collection")
else:
return GroupCollectionPermission.objects.filter(
group__user=user,
collection=collection
).select_related("permission", "collection")
# END PATCH
from wagtail.permission_policies.collections import CollectionPermissionLookupMixin
CollectionPermissionLookupMixin.get_all_permissions_for_user = mutitenant_get_all_collection_permissions_for_user
Collection Management
Collection management permissions allow admins to create their own nested set of collections. As you
can see in the diagram below, the CollectionManagementPermissionPolicy’s permissions also all flow
through get_all_permissions_for_user so the patch above that we used for managing items stored
in collections takes care of most of the policy changes needed for managing the collections
themselves.
Collection Management Permissions
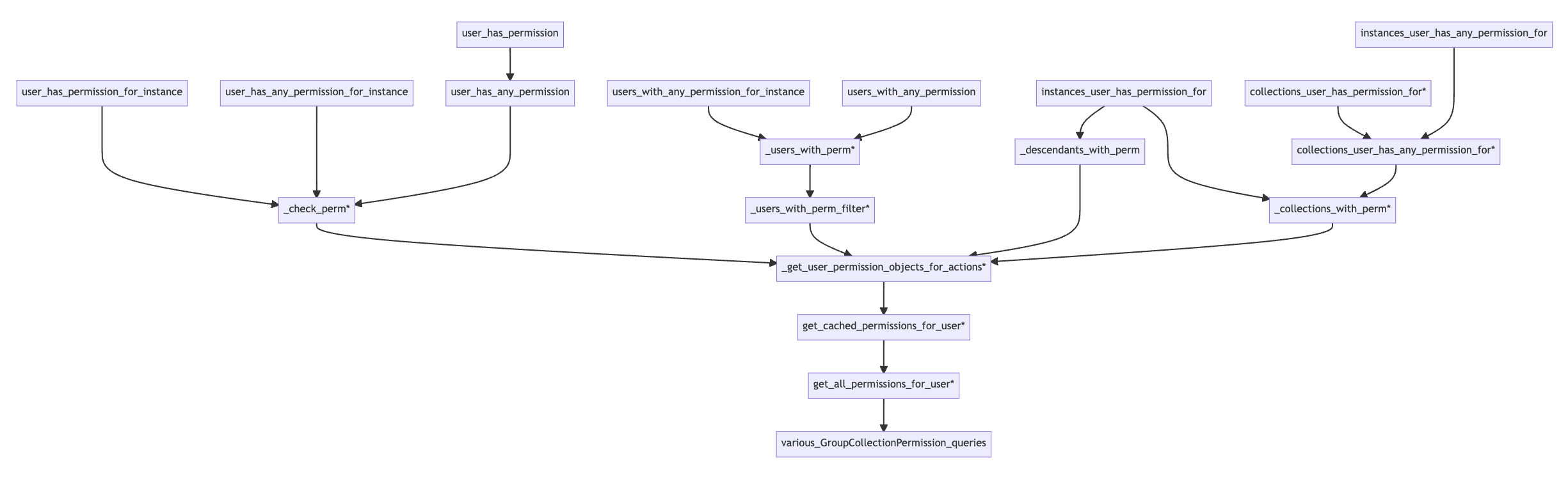
The one additional thing we need to patch is a helper method used to decide which collections a user
may delete: _descendants_with_perm. (If we omit this patch, admin’s can’t delete any collections).
def multitenant__descendants_with_perm(self, user, action):
"""
Return a queryset of collections descended from a collection on which this user has
a GroupCollectionPermission record for this action. Used for actions, like edit and
delete where the user cannot modify the collection where they are granted permission.
"""
# Get the permission object corresponding to this action
permission = self._get_permission_objects_for_actions([action]).first()
# BEGIN PATCH
# Replace the check for permission on the User's full list of Groups to a check for
# permissions on only the current Site's Groups. Also take SuperAdmins into account.
request = get_current_request()
if not request:
logger.error('In CollectionManagementPermissionPolicy.multitenant__descendants_with_perm but could not get the request.')
return Collection.objects.none()
site = Site.find_for_request(request)
collection = Collection.objects.filter(name=site.hostname).first()
# Fill in SuperAdmin groups
if user.is_superadmin:
groups = Group.objects.filter(name=f'{site.hostname} Admins').all()
else:
# user.groups.all() is what is in the original; we could restrict by site but the collection
# filter will remove permissions not relevant to this site
groups = user.groups.all()
# Get the collections that have a GroupCollectionPermission record
# for this permission and any of the user's groups; create a list of their paths
# PATCH: restrict to collections belonging to this site
collection_roots = Collection.objects.descendant_of(collection, inclusive=True).filter(
group_permissions__group__in=groups,
group_permissions__permission=permission,
).values("path", "depth")
# END PATCH
if collection_roots:
# build a filter expression that will filter our model to just those
# instances in collections with a path that starts with one of the above
# but excluding the collection on which permission was granted
collection_path_filter = Q(
path__startswith=collection_roots[0]["path"]
) & Q(depth__gt=collection_roots[0]["depth"])
for collection in collection_roots[1:]:
collection_path_filter = collection_path_filter | (
Q(path__startswith=collection["path"])
& Q(depth__gt=collection["depth"])
)
return Collection.objects.all().filter(collection_path_filter)
else:
# no matching collections
return Collection.objects.none()
from wagtail.permission_policies.collections import CollectionManagementPermissionPolicy
CollectionManagementPermissionPolicy._descendants_with_perm = multitenant__descendants_with_perm
Permissions for other models
We also need per-site permissions to manage other kinds of models - Snippets in Wagtail’s terminology. Please see the last section of Snippets for the code we use in our authentication backend.